As we become increasingly dependent on AI, an important question arises: Will this dependency help smaller languages and alphabets survive, or will it hasten their path toward oblivion? Will AGI ever speak Serbian?
As Serbian language can be written using two different alphabets, which one will the LLMs think in?
It’s a tough question, and in this blog post I’ll try to explore LLM’s knowledge of both alphabets and the implications it has on current writing patterns and data availability.
Serbian’s digraphic alphabet
Most languages have a single alphabet used for writing. Some are more complex, like Japanese, which simultaneously uses three different alphabets.
The Serbian language is among the rare few languages that are digraphic, meaning it has two alphabets, each of which can independently express the language fully. Cyrillic is the traditional alphabet, while Latin is considered more modern.
For many centuries, the Cyrillic alphabet was the dominant writing system in Serbia. However, due to historical and political factors—and particularly because we live in the digital age, where English is today’s lingua franca—the traditional Cyrillic alphabet is becoming less common.
Cyrillic and Latin alphabets
People have varied opinions regarding the state and usage of the Cyrillic alphabet. Some actively advocate for its preservation, viewing it as an essential part of Serbia’s cultural heritage. Others strongly emphasize that both alphabets are equally valid and argue that forcing either alphabet upon people is counterproductive, as language is naturally dynamic and evolving. Most people, however, remain indifferent, as they are fluent in both alphabets.
Online presence
Yet the fact remains that Cyrillic usage is declining. It is clearly evident that Latin script has become far more prevalent across media, street signs, and daily communication. According to reports from a few years ago (Politika, Danas)—with the gap likely wider today—the usage ratio of Latin to Cyrillic is approximately 60–70% to 40–30%.
Common Crawl—a snapshot representing a significant portion of the internet—can help us estimate the online presence of different languages:
Language
Percentage of Internet Text Data [%]
Serbian
0.22
Croatian
0.23
Bosnian
0.05
English
43.50
Other
56.00
Serbian, Croatian, and Bosnian are highly similar languages. Until roughly 25 years ago, they were officially considered a single language known as Serbo-Croatian. For the purpose of this analysis, we’ll treat them as one language group.
The Croatian language (almost) exclusively uses the Latin alphabet, while Serbian and Bosnian employ both Cyrillic and Latin scripts. Based on the previously mentioned estimates, we assume that approximately 40% of Serbian and Bosnian text is written in Cyrillic. Using this assumption, we can calculate the relative usage of each alphabet:
This calculation indicates that the Latin alphabet is used roughly four times more frequently than Cyrillic.
The experiment
In this project I tested different (small) LLMs to see how well they work if given the same tasks in Cyrillic and Latin alphabets, and compare that to English baselines.
There are popular datasets used for testing LLMs in various fields:
Common sense - how well can an LLM reason about simple problems?
Datasets that test this are: Hellaswag, Winogrande, PIQA, OpenbookQA, ARC-Easy, ARC-Challenge
World knowledge - how much information does it know about the world?
NaturalQuestions, TriviaQA
Text understanding - how well can it extract information from a given piece of text?
BoolQ
These are very basic benchmarks, and many more exist today. For example Frontier Math that tests LLMs capabilities in doing math, or Humanity’s Last Exam that contains extremely difficult problems from a variety of subjects, that even the human experts in those fields have trouble solving.
Getting the data
To the best of my knowledge, there previously wasn’t a Cyrillic dataset suitable for standard LLM benchmarks. Last year, Aleksa Gordic and several other contributors made a commendable effort by translating popular English datasets into Serbian (Latin). Building upon their work, I created the Cyrillic datasets by transcribing the existing Latin versions. These datasets are available here.
Examples
Here are examples of differents tasks that the LLM was tested on.
Common sense test
The LLM is given the first part of the sentence and needs to decide which of the following parts make most sense.
Input: After opening the freezer, Peter found out that _________
Options:
there was no icecream left
Earth is a globe
the TV was turned on
it’s Monday
The model should pick option number 1, as it makes the most common sense.
World knowledge
Could be a very basic example:
Question: What’s the capital of France?
Answer: Paris
or
Question: What mythological beast has the head of a man, the body of a lion, and the tail and feet of a dragon?
Answer: manticore
If you were wonderting what a manticore looks like
Text understanding
The model needs to aswer “true” of “false” based on the text it’s been provided.
Provided text (truncated):
All biomass goes through at least some of these steps: it needs to be grown, collected, dried, fermented, distilled, and burned. All of these steps require resources and an infrastructure. The total amount of energy input into the process compared to the energy released by burning the resulting ethanol fuel is known as the energy balance (or ``energy returned on energy invested’’)….
Question:
Does ethanol take more energy make that produces?
The correct answer is “false”.
Models used
I conducted the experiments primarily on my Mac and a single A100 GPU. This setup limited my tests to relatively smaller language models, up to around 8 billion parameters (8B). While this is orders of magnitude smaller than renowned models like OpenAI’s GPT-4 or Anthropic’s Claude Sonnet, these smaller-scale models remain highly relevant. They are increasingly finding their way onto our laptops, smartphones — and soon perhaps even our refrigerators and ovens.
The models used:
Model Name
Size (billions of parameters)
Qwen/Qwen2.5-0.5B-Instruct
0.5
meta-llama/Llama-3.2-1B-Instruct
1.0
Qwen/Qwen2.5-1.5B-Instruct
1.5
meta-llama/Llama-3.2-3B-Instruct
3.0
meta-llama/Llama-3.1-8B-Instruct
8.0
Results
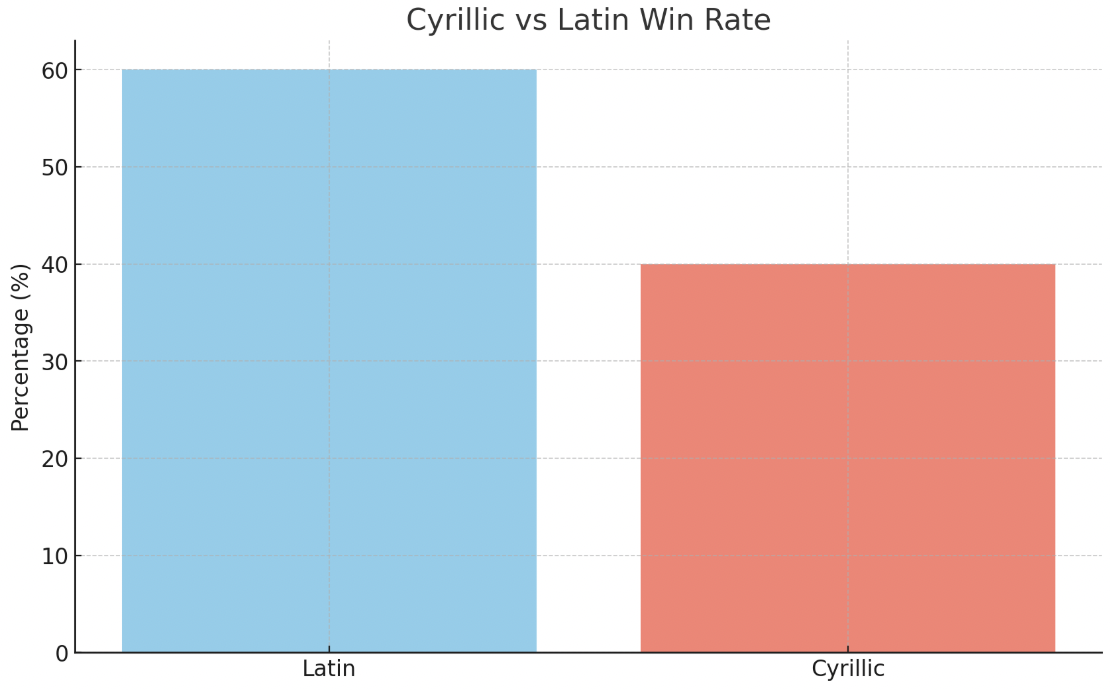
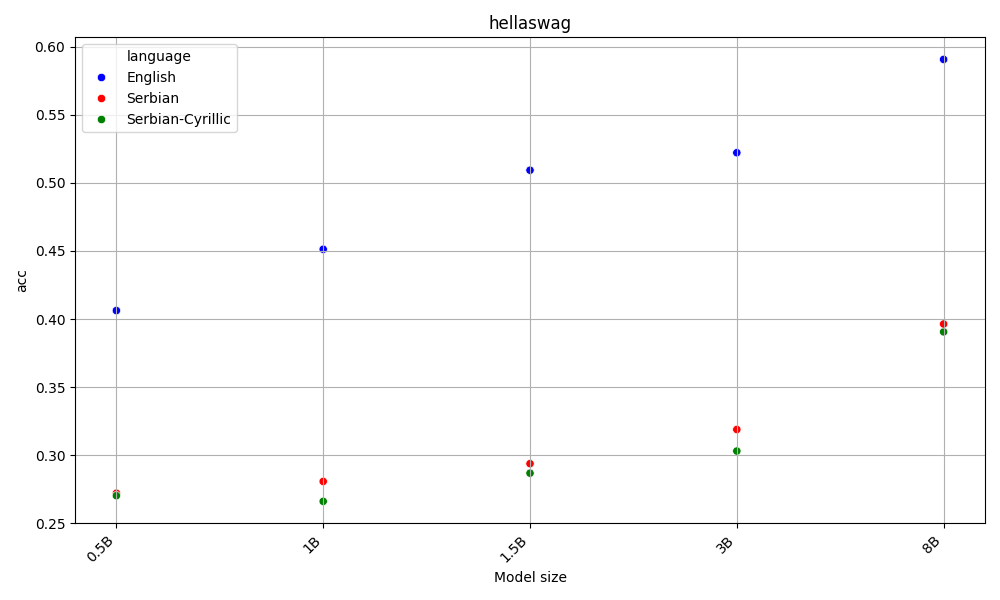
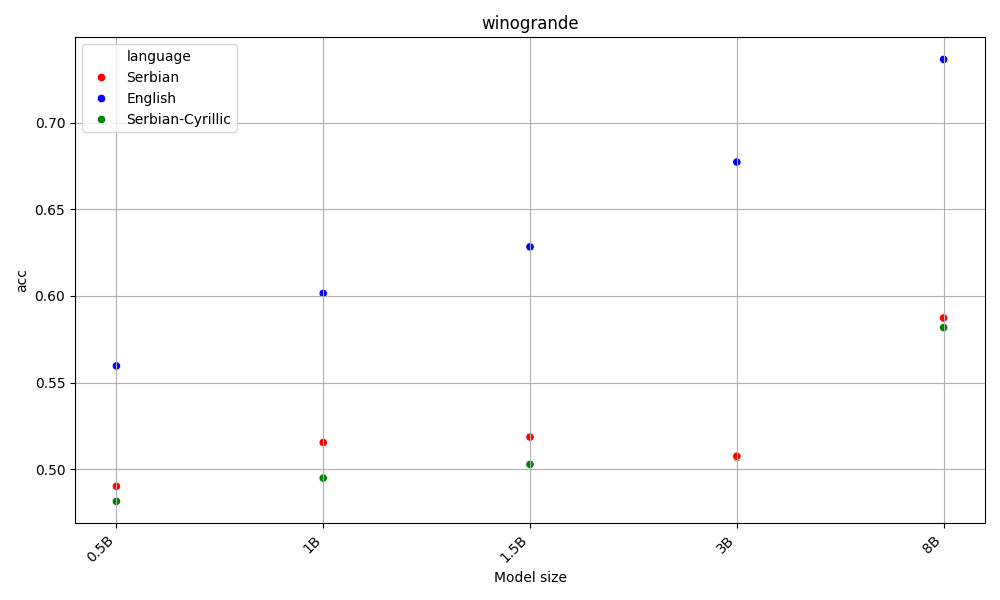
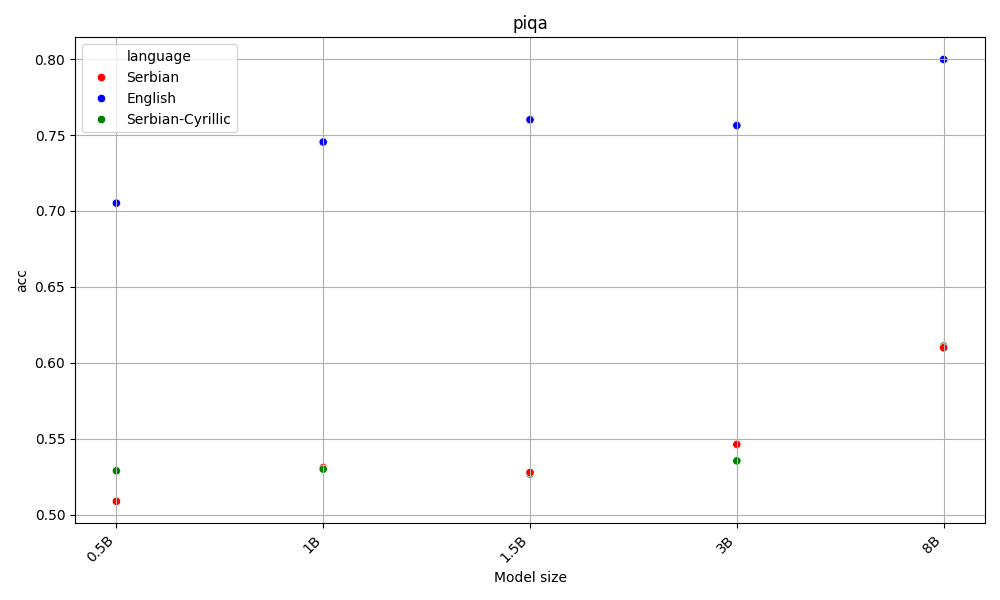
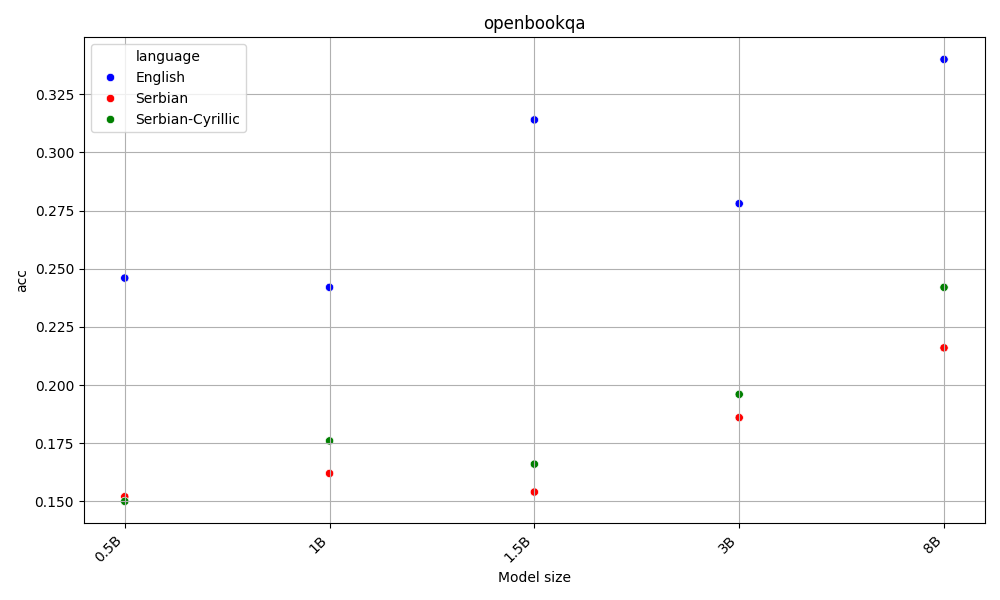
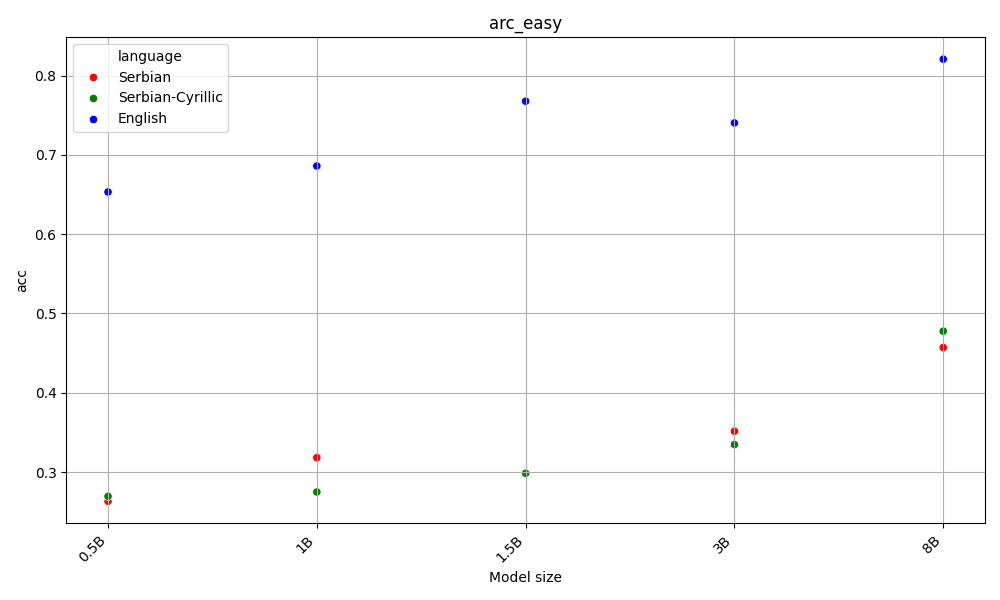
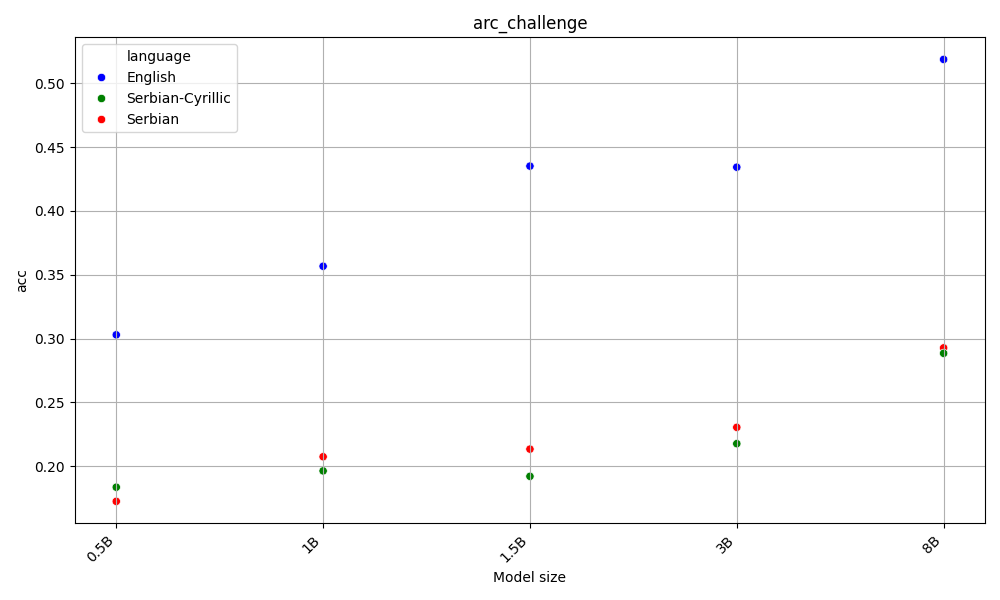
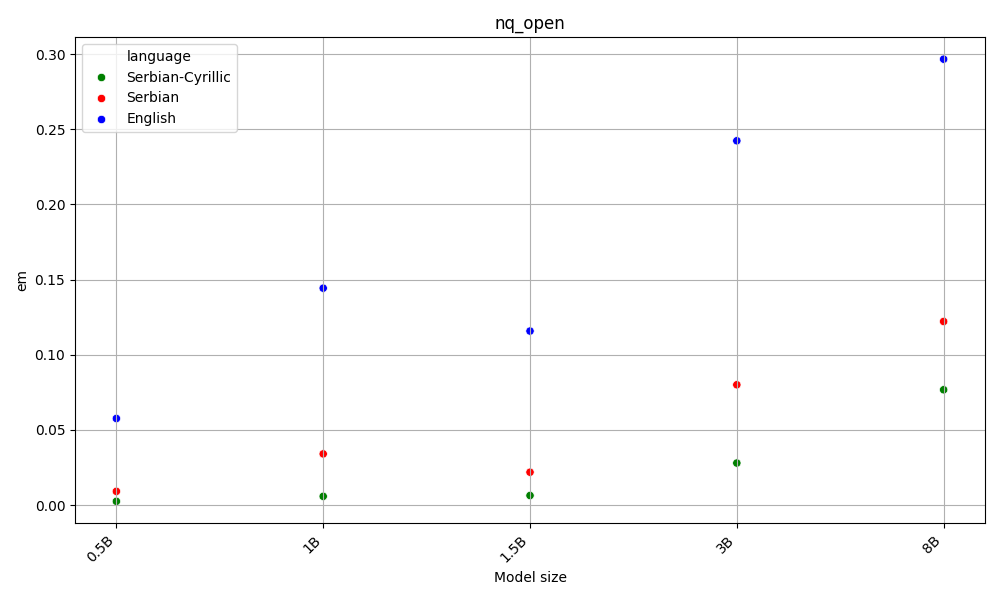
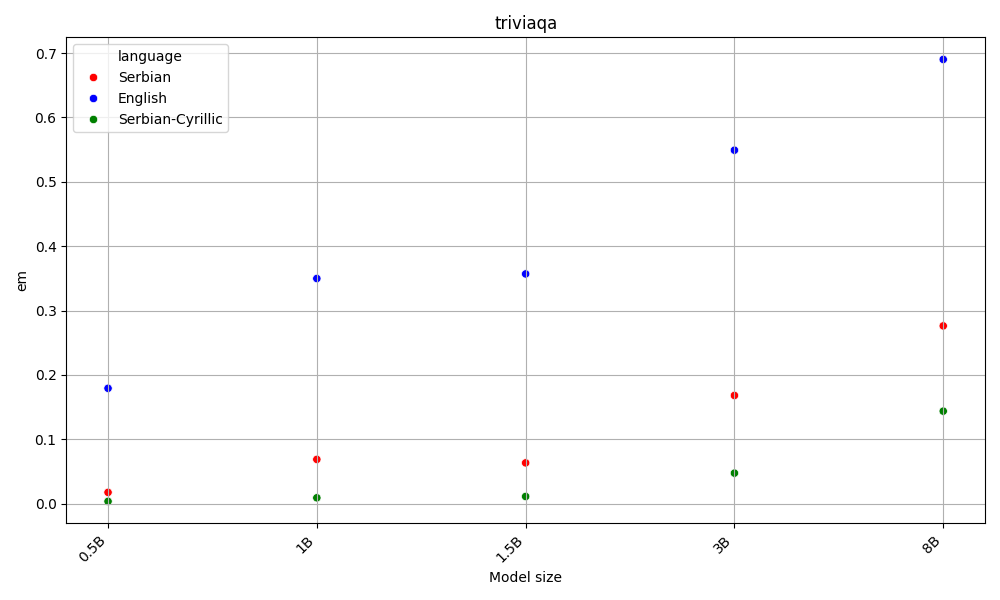
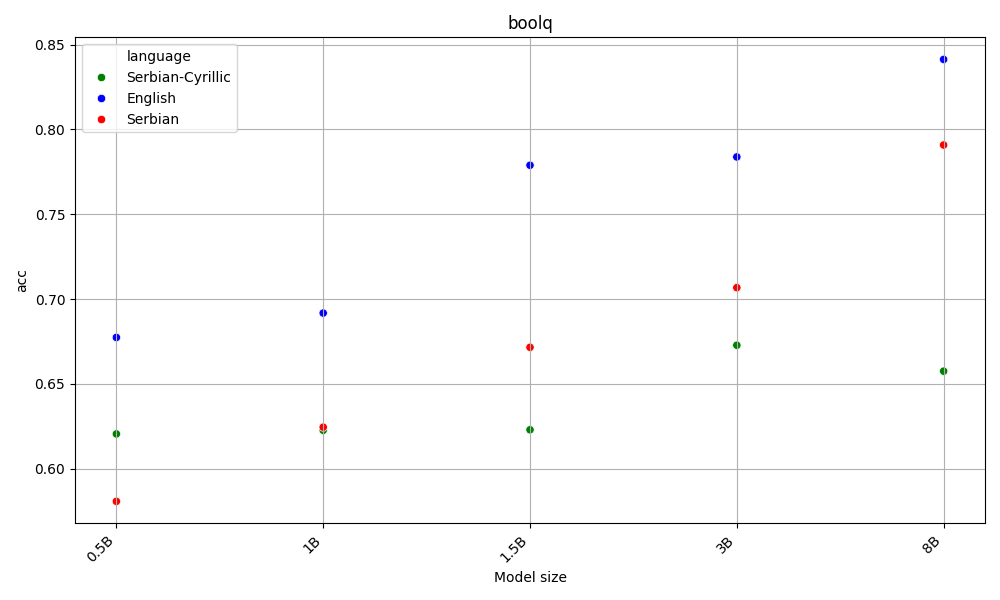
Latin beats Cyrillic on 60% of the benchmarks, across all model sizes. Both are far behing English, the language of the AI gods.
This is aligned with the hypothesis that as latin alphabet is more widespread, LLMs are better at it. Detailed results for each task are available in the Appendix.
Latin vs Cyrillic win rate
However, I was expecting a bigger gap. The performance difference is X on average, between the Serbian alphabets.
On the other hand, English beats Serbian on every task and model size, with Y.
Both Serbian alphabets have similar scores, which are far behind English.
What I though the results would shown vs what they actually show
Tokenization and $$$
There is another important factor that impacts the performance, and price, when using differnet alphabet - tokenization.
TL;DR: The LLMs don’t actually process words, they process tokens and conversion form text to tokens is the first step in the LLM.
Tokenization is a huge topic, but the simplest way of explaining it is as mapping from free form text to a list of “words” from a dictionary.
Here’s a tokenization example with cl100k_base tokenizer (gpt-4o’s tokenizer):
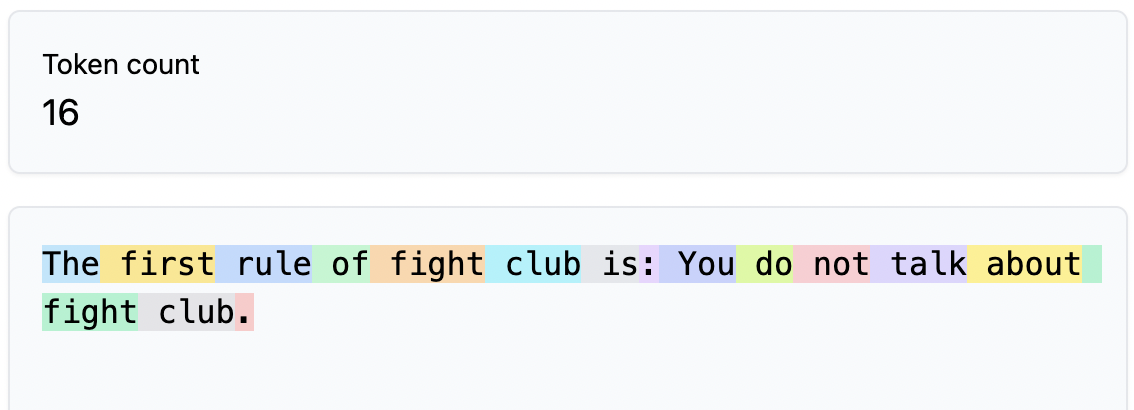
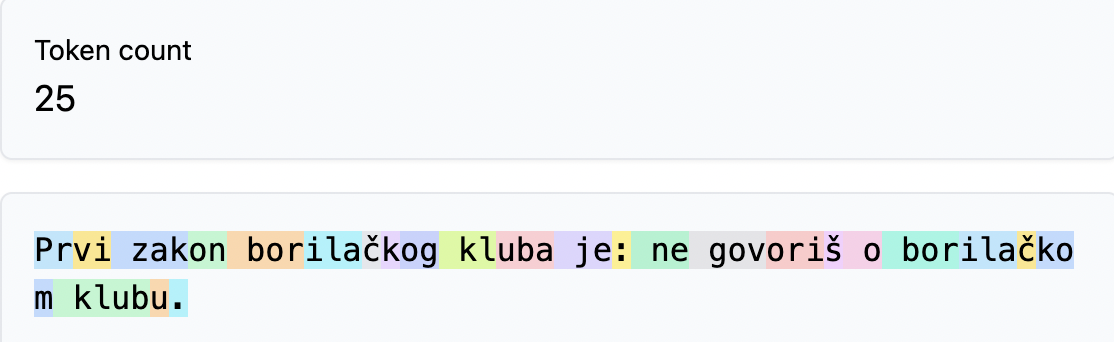
An important takeway here is that for the same (logical) sentence, the amount of tokens varies a lot based on the language.
English language needs the least amount of tokens (15), Latin (25) more and Cyrillic (30) the most.
This has the following implications:
LLMs tend to have better performance when they need fewer tokens to represent the sentence (TODO ADD A CITATION?). Tokenizers are trained in a way to use less tokens for representing more common text. As English is much common that Serbian, it uses less tokens than for Serbian. Same goes for Latin and Cyrillic.
The more tokens are used, the more expensive it is to use them. It’s standard for LLM providers to charge by the number of input and output tokens.
The more tokens a model uses, the longer it takes to produce output.
The 15 -> 25 -> 30 tokens might sound like not much, but this is how it scales to the full dataset used in this experiment.
When using cl100k_base tokenizing, which is the default tokenizer for ChatGPT it takes a lot more tokens to process Serbian than English:
Tokenizer
Language
Number of tokens
Estimated input price ($)
cl100k_base
Serbian-Cyrillic
82,580,952
$165.16
cl100k_base
Serbian-Latin
68,423,105
$136.85
cl100k_base
English
51,612,744
$103.23
o200k_base
Serbian-Cyrillic
65,421,633
$130.84
o200k_base
Serbian-Latin
54,738,484
$109.48
o200k_base
English
42,290,195
$84.58
Based on pricing from sometime in March 2025
This means that just for reading the dataset, it costs 60% more to do it in Serbian - Cyrillic than in English.
Looking at the results from previous section and the tokenization pricing -> using Latin produces higher quality outputs, while being cheaper and faster.
Limitations
Transcribing the dataset introduced some noise, and the Cyrillic data could be cleaner. E.g “CSI Miami” is now “ЦСИ Миами”, which doesn’t make much sense. An easy way to fix this would be to run the input dataset through some SOTA LLM and ask it to fix the transcriptions (e.g. with GPT-4o or Sonnet).
Since this experiment was done, many newer open source models were released, so it should be good to test with those variants.
Conclusion
Both Serbian alphabets have worse performance than English AI - by a significant margin. Latin performs better than Cyrillic in most cases, but that difference is very small. I was hoping to see a difference in the output quality between the 2 Serbian alphabets, but have shown that it’s small.
As people want to use the frontier models, which are tuned primarly for English, the question remains - will people (un)willingly stop using Serbian if it yields them worse results from the ultimate AI companions?
My take is that for most of our daily tasks (summarization, simple QA) majority of today’s models already contain the necessary skills. But for solving the hardest tasks - engineering, research, complicated business analysis - people will reach for English SOTAs.
Appendix - figures and detailed results for each task